Blog
What is a data strategy? Components, frameworks & why it matters

You've probably seen this play out: one team builds a dashboard on data that another team doesn't trust, a third team extracts the same dataset into a separate pipeline, and nobody agrees on which customer numbers are correct. Meanwhile, leadership greenlights an AI initiative that depends on data quality nobody can actually verify.
A data strategy defines how an organization collects, stores, manages, and uses data. It connects people, processes, and technology into a cohesive approach that supports measurable business goals, from revenue growth to regulatory compliance. Without one, teams end up building on a foundation of conflicting sources, stale records, and duplicated effort.
This article covers the core data strategy components, including business alignment, architecture, quality, governance, team structure, and change management, and why each one matters for building a data program that delivers results.
Why you need a data strategy
Without a data strategy, nobody agrees on what data matters, who owns it, or how it should reach the teams and apps that depend on it. The result is predictable: slow business processes, decisions made on stale or incomplete information, and data siloed across business units that each maintain conflicting sources of truth. Poor data quality also wastes resources and undermines decision-making. For organizations building AI apps, the problem compounds because AI models are only as reliable as the data they're trained on and retrieve from. A data strategy isn't just an operational concern. It's the foundation of any credible AI initiative.
Comparing data-centric & data-driven organizations
Before building a strategy, it helps to know where your organization sits today. Data-centric and data-driven organizations are not the same, and most teams overestimate how far along they are.
| Data-centric | Data-driven | |
|---|---|---|
| Focus | Data as an asset to collect and analyze | Data as a driver of operational change |
| Use of data | Informs decisions | Actively changes strategy and operations |
| Technology emphasis | Data storage, cataloging, governance | Predictive analytics, machine learning |
| Competitive role | Data as a valuable resource | Data as a mechanism for continuous adaptation |
Organizations typically start data-centric and evolve toward data-driven as their capabilities and culture mature. The components below are what make that progression possible.

Data-driven vs. data-centric decisions
The key components of a data strategy
A complete data strategy spans six areas, from how you align data work to business goals through to how you manage the organizational change required to make it stick. These areas are interconnected, so weakness in any one of them limits what the whole strategy can achieve.
Business strategy alignment
Business alignment ties data work directly to business goals. If a data initiative runs independently of those goals, it tends to produce accurate answers to the wrong questions—and nobody notices until the budget's already spent.
Executive support matters here. Data initiatives often stall when they conflict with existing priorities, and without leadership backing, they're the first thing to get deprioritized. Alignment means identifying specific, measurable objectives tied to revenue growth, operational efficiency, or risk management, and then building a roadmap that sequences those objectives against realistic constraints like budget, staffing, and competing initiatives.
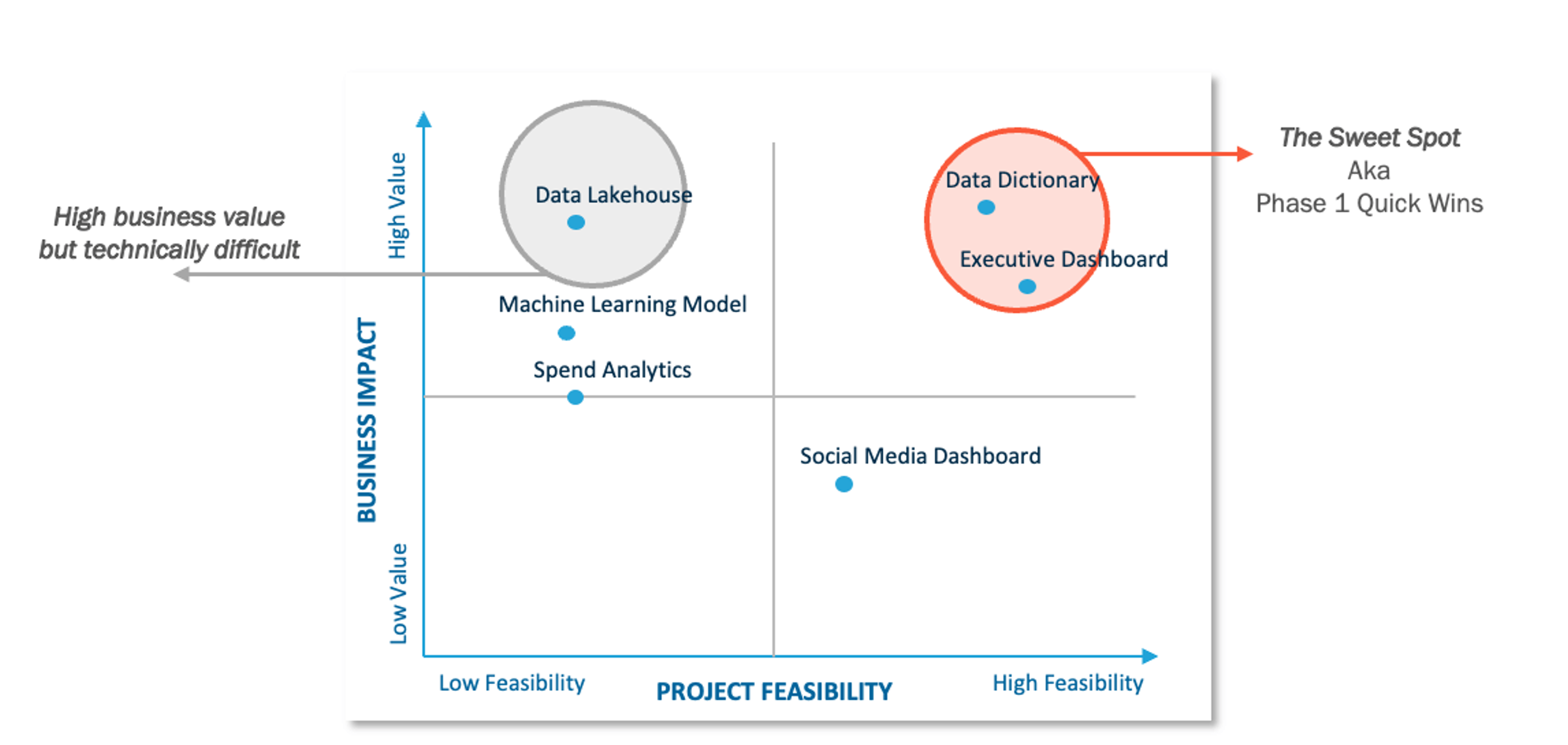
Prioritization matrix
Data maturity assessment belongs in this phase too. Before committing to a roadmap, you need an honest picture of where you actually stand: which data assets exist, which processes work, and which gaps need to be closed before more ambitious goals become achievable. Skip this step, and you'll end up with a roadmap that assumes capabilities your organization doesn't have yet.
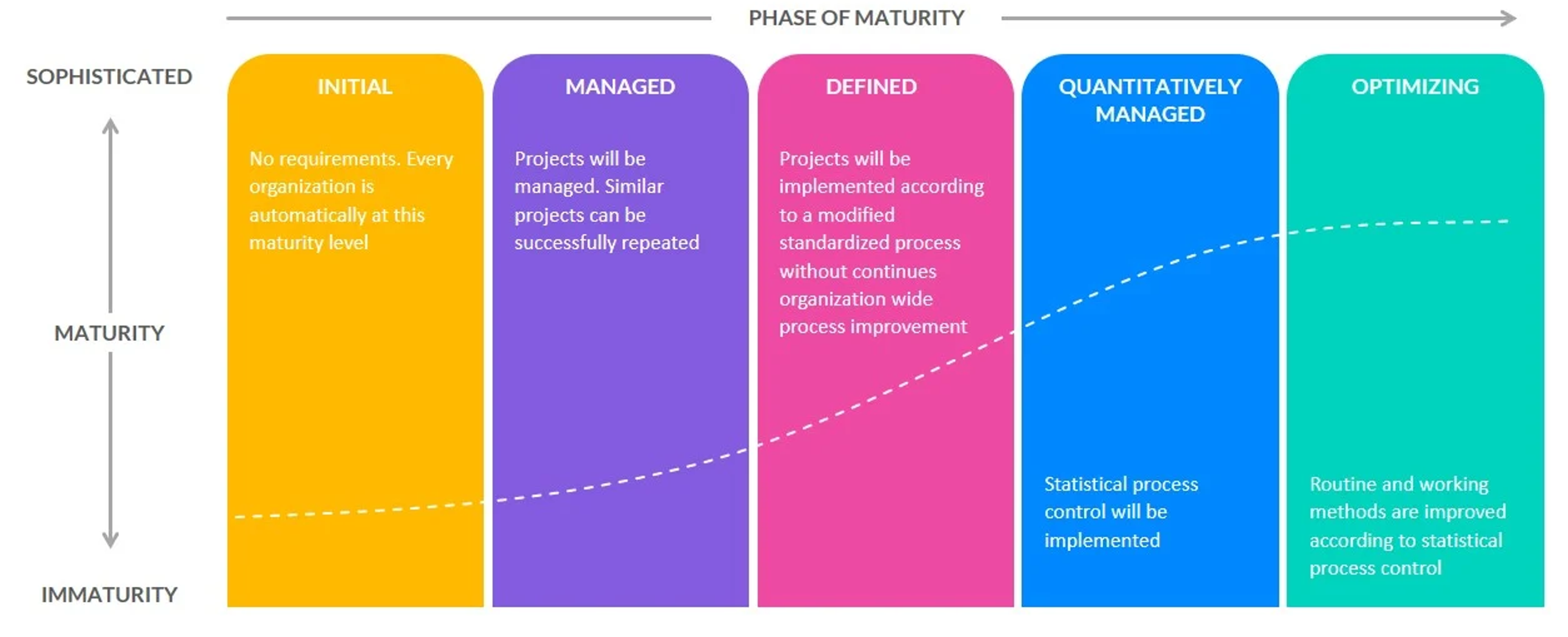
Data maturity assessment
Data architecture & infrastructure
Once business goals are set, architecture determines whether data can actually reach the people and systems those goals depend on. Data architecture defines how data moves through your organization—the blueprint for how data gets identified, ingested, stored, transformed, and made available for analysis and app use.
A well-designed architecture simplifies scaling, reduces duplication, and makes data accessible where it's needed. Building one starts with figuring out what data actually exists across the organization. A data catalog helps here, mapping datasets to their owners and documenting how data flows through the business. From there, you need to decide how to store and consolidate that data, whether in a data warehouse, a data lake, or a combination, and how to connect disparate sources through data pipelines that can ingest, transform, and deliver data in usable form.
One dimension that most traditional frameworks underemphasize is data velocity, the speed at which data needs to be available for operational use. Analytical workloads like reporting and historical trend analysis can handle latency measured in minutes or hours. But operational use cases like real-time personalization, fraud detection, session management, and AI inference need data that's current within milliseconds. If your architecture only accounts for the analytical layer and ignores the operational layer, you'll hit a wall the moment your apps need to act on data in real time. A complete data architecture strategy designs for the latency requirements of each use case explicitly.

Get started with Redis for faster apps
Get started with Redis for real-time AI context and retrievalData quality management
Good architecture gets data where it needs to go, but data quality management determines whether what arrives is actually worth using. You can build a great architecture, but if it's storing and moving low-quality data efficiently, you're just producing bad outputs faster.
For organizations building AI apps, quality matters even more because weak source data undermines model performance and erodes trust in the results. Data quality management covers the processes for defining quality standards, identifying and correcting errors, deduplicating records, enforcing data types and formats, and monitoring quality over time. It also depends on clear data ownership, which the team structure section below addresses.
The goal isn't perfect data, because that's not achievable at scale. The goal is data that's consistently reliable enough for the decisions and apps that depend on it.
Data governance
Quality standards don't enforce themselves, which is where governance comes in. Data governance defines the rules, processes, and accountabilities that keep a data strategy running over time. It determines who can access which data, under what conditions, and for what purposes.
Governance also keeps those rules aligned with business objectives and regulatory requirements. Many organizations now treat governance as an operational discipline rather than a compliance checkbox, and the ones that do it well treat governance as something that helps people use data, not something that blocks them. The goal is controlled access, not restricted access.
For organizations with AI programs, governance scope is expanding. As GenAI use cases multiply, governance frameworks built only for structured, tabular data need to evolve to cover unstructured data too. If you're building a forward-looking data strategy, that shift should be part of the plan from the start.
The data strategy team
A data strategy needs a clear operating model as much as it needs technology. The right people, roles, and decision rights determine whether the strategy can actually run.
Data strategy teams typically include a combination of technical and business roles, structured around one of three operating models.
- A decentralized operating model gives each business unit ownership of its own data assets within shared standards. It scales well but can fragment definitions and tooling across teams.
- A centralized operating model puts data ownership and governance under a single function, often a Chief Data Officer (CDO). It simplifies decision-making but can bottleneck large organizations.
- A hybrid model centralizes governance standards while distributing execution to business units. This is where most large enterprises converge as they scale.
Common roles in a data strategy team include data engineers, data architects, data scientists, data analysts, business analysts, data managers, and the CDO. What matters more than the exact titles is clarity about who owns what, which data, which processes, and which decisions. Vague accountability is one of the most consistent reasons data strategies fail in execution.
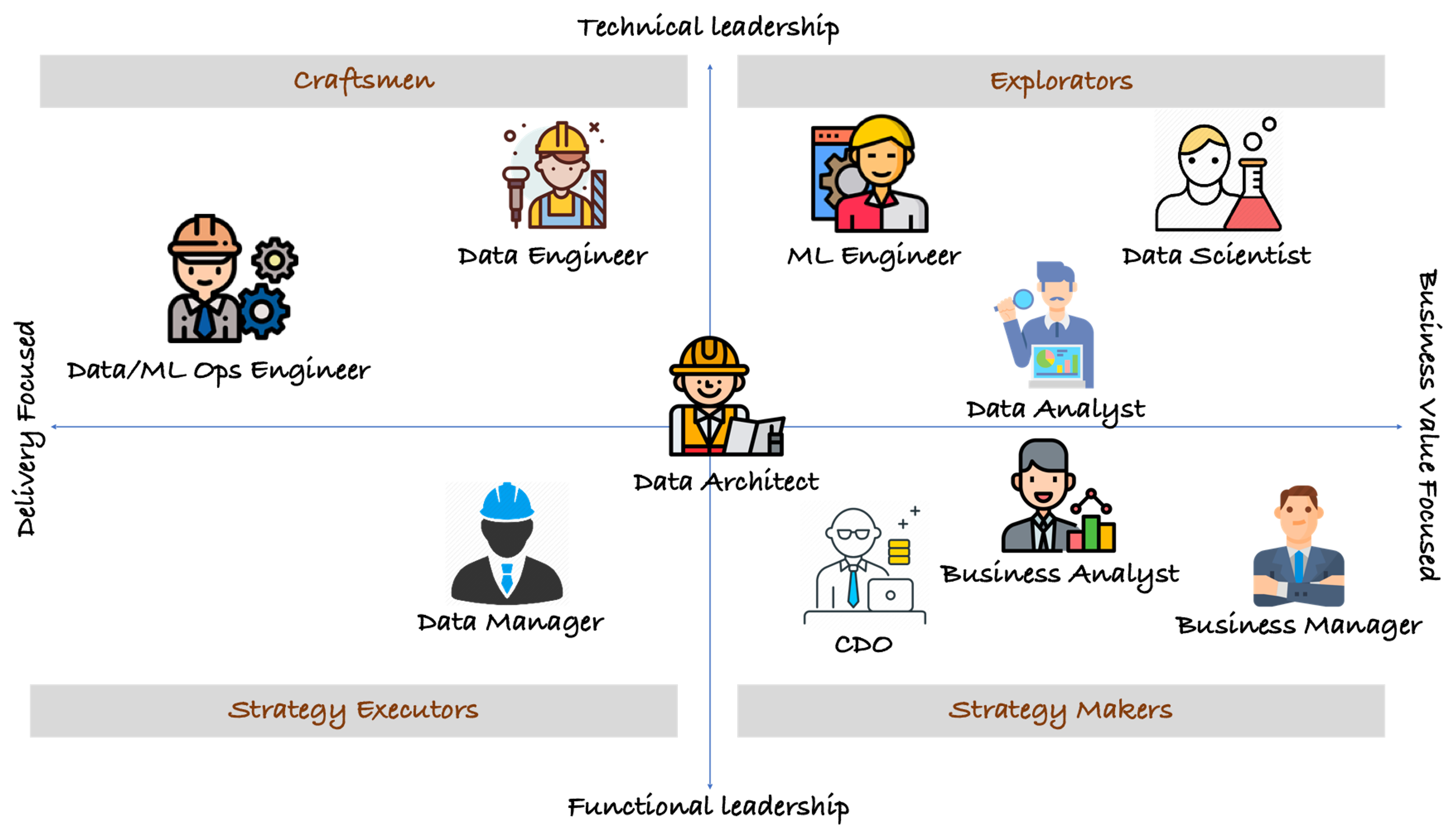
The data team
Change management
Even with the right team in place, a data strategy only works if people actually change how they work. After governance, architecture, and team structure are defined, organizations still need adoption.
New data architectures, governance policies, and quality standards all require change, and organizations that underestimate that cultural dimension rarely see the outcomes they planned for. Effective change management means communicating clearly about why changes are happening, what the benefits are for different stakeholders, and how teams will be supported through the transition. Data literacy training, hands-on technical support, and transparent progress reporting all help—and the leadership backing described in business alignment is just as important here.

Build faster with Redis Cloud
Get Redis up and running in minutes, then scale as you grow.Good strategy needs fast infrastructure
A data strategy gives organizations the structure to turn data from a byproduct of operations into a genuine business asset. Business alignment, architecture, data quality, governance, team structure, and change management all reinforce each other—and gaps in one area undermine the rest.
One dimension worth emphasizing: if your strategy doesn't account for data velocity from the start, you'll likely need to retrofit it later at higher cost. Redis provides an in-memory real-time data platform for operational and AI workloads where latency directly affects outcomes, combining vector search, caching, and data structures in a single layer so you don't need to stitch together separate systems for each capability.
If you're designing or refreshing a data strategy, try Redis free to see how real-time data infrastructure fits into your architecture, or talk to our team about your specific needs.
FAQs about data strategy
How do you conduct a data maturity assessment?
A data maturity assessment evaluates your organization across five capability dimensions: data governance and ownership accountability, technical infrastructure and integration capability, data quality and consistency practices, analytics and reporting maturity, and data culture including literacy and adoption patterns. Most frameworks use a five-level scale ranging from ad hoc practices through repeatable processes to optimized and continuously improving capabilities.
Start with stakeholder interviews and audits of existing data assets to document actual workflows rather than ideal ones. Map your current systems, data flows, and tooling gaps, and measure culture through surveys that reveal how teams make decisions and whether they trust available data. The output should be a scored maturity profile that identifies gaps between current state and the capabilities your business objectives require, which then informs sequencing decisions in your roadmap.
What are best practices for becoming a data-driven organization?
Transitioning from data-centric to data-driven requires embedding analytics into daily workflows rather than treating it as a separate function. Identify high-impact decisions that currently rely on intuition or delayed reporting, then build feedback loops where data insights automatically trigger operational responses. Invest in self-service analytics tools that let business users explore data without always depending on data teams, and shift performance metrics to measure outcomes influenced by data rather than just data availability or quality scores.
Cultural change matters most in this transition—leaders need to model data-informed decision-making consistently and create psychological safety for teams to challenge assumptions with evidence. Focus on quick wins that demonstrate measurable business impact early, since visible success builds organizational momentum and makes it easier to secure ongoing investment.
How should a data strategy support AI & machine learning?
Adapting a data strategy for AI and machine learning (ML) means building versioning systems for training datasets and model artifacts, pipelines that support both batch processing and real-time feature serving, and data lineage tracking that captures the full chain from raw data through feature engineering, model training, and inference outputs. Plan for significantly higher storage and compute costs since ML workloads tend to consume far more resources than traditional analytics.
Incorporate feedback loops that capture model predictions alongside actual outcomes, creating labeled datasets that help retrain models and measure performance degradation over time. This turns production systems into continuous learning environments rather than static deployments.
How do you choose between centralized, decentralized, & hybrid data team operating models?
The right model depends on three factors: how many distinct business units generate and consume data, how much standardization your compliance environment requires, and how fast individual teams need to move. If regulatory requirements demand tight control over definitions and access, centralization makes sense even at the cost of speed. If business units operate in fundamentally different domains with little shared data, decentralization avoids bottlenecks. Teams tend to land on a hybrid model as they scale because neither extreme holds up — the practical question is which decisions to centralize (usually governance standards and core infrastructure) and which to distribute (usually tooling choices and execution).
How do you design a data architecture for both analytical & operational workloads?
The most common pattern is a dual-layer architecture connected by change data capture or event streaming. Writes flow to a system of record (typically a relational database or data lake), while change events simultaneously feed an in-memory operational layer that serves low-latency reads. This gives analytical systems the eventual consistency they can tolerate while keeping operational systems current. The key design decisions are which data needs to be replicated to the operational layer (not everything does), how freshness is maintained (polling vs. streaming), and how to handle schema changes across layers without breaking downstream consumers. Build bidirectional flows so ML models trained on historical data in the analytical layer can push predictions into the operational layer for real-time serving. Set separate latency service-level objectives for each layer based on actual business requirements rather than applying uniform targets across both.
Get started with Redis today
Speak to a Redis expert and learn more about enterprise-grade Redis today.